
Faster time parsing
A story in 3 acts
Here at Ravelin we have a lot of data with a lot of timestamps. Most of the timestamps are stored as strings in BigQuery, and most of our Go structs represent time with the Go time.Time type.
I say these facts above with regret. We really do have a lot of data. And we really do have a lot of timestamps. For some time I’ve been circling around a conclusion, and as more time passes I’m certain I’ll fall toward it:
Friends don’t let friends represent time in databases as strings.
Anyway, decisions have been made and we are stuck with them.
But being stuck with the decision doesn’t mean we’re stuck with all the unfortunate consequences.
We can make the best of things.
And, for me, making the best of things now inevitably includes finding a faster way to parse RFC3339 timestamps than using time.Parse.
It turns out this is pretty easy. time.Parse has two parameters: one that describes the format of the data to parse, and another that is the data string that needs parsing.
The format parameter does not just select a dedicated parsing routine appropriate for that format.
The format parameter describes how the data should be parsed.
time.Parse not only parses the time, but has to parse, understand and implement a description of how to parse the time.
If we write a dedicated parsing routine that just parses RFC3339 it should be faster than that.
But before we start, let’s just write a quick benchmark to see how fast time.Parse is.
func BenchmarkParseRFC3339(b *testing.B) {
now := time.Now().UTC().Format(time.RFC3339Nano)
for i := 0; i < b.N; i++ {
if _, err := time.Parse(time.RFC3339, now); err != nil {
b.Fatal(err)
}
}
}
Here are the results.
name time/op
ParseRFC3339-16 150ns ± 1%
Now we can write our dedicated RFC3339 parsing function. It’s boring. It isn’t pretty. But (as far as I can tell!) it works.
(It really is quite long and not very pretty, so rather than include it in this post and make you all scroll past it, here is a link to the final version with all the optimisations discussed below applied. If you imagine a great long function with quite a few calls to strconv.Atoi you’ll get the picture)
If we tweak our benchmark to use our new parsing function we get the following results.
name old time/op new time/op delta
ParseRFC3339-16 150ns ± 1% 45ns ± 4% -70.15% (p=0.000 n=7+8)
It’s really quite a lot faster than time.Time. Great. We’re done.
Of course we’re not done.
If we get a CPU profile we see lots of our time is now taken in calls to strconv.Atoi.
> go test -run ^$ -bench BenchmarkParseRFC3339 -cpuprofile cpu.prof
> go tool pprof cpu.prof
Type: cpu
Time: Oct 1, 2021 at 7:19pm (BST)
Duration: 1.22s, Total samples = 960ms (78.50%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 950ms, 98.96% of 960ms total
Showing top 10 nodes out of 24
flat flat% sum% cum cum%
380ms 39.58% 39.58% 380ms 39.58% strconv.Atoi
370ms 38.54% 78.12% 920ms 95.83% github.com/philpearl/blog/content/post.parseTime
60ms 6.25% 84.38% 170ms 17.71% time.Date
strconv.Atoi converts numbers in ASCII strings to integers.
That’s a fundamental part of the Go standard library, so it’s bound to be really well coded, and optimised already.
Surely we can’t improve on that?
Well, most of our numbers are exactly 2 bytes long or exactly 4 bytes long. We can write number parsing functions that take advantage of these facts and don’t have any of those nasty slow for-loop things.
func atoi2(in string) (int, error) {
a, b := int(in[0]-'0'), int(in[1]-'0')
if a < 0 || a > 9 || b < 0 || b > 9 {
return 0, fmt.Errorf("can't parse number %q", in)
}
return a*10 + b, nil
}
func atoi4(in string) (int, error) {
a, b, c, d := int(in[0]-'0'), int(in[1]-'0'), int(in[2]-'0'), int(in[3]-'0')
if a < 0 || a > 9 || b < 0 || b > 9 || c < 0 || c > 9 || d < 0 || d > 9 {
return 0, fmt.Errorf("can't parse number %q", in)
}
return a*1000 + b*100 + c*10 + d, nil
}
If we run our benchmark again we can see we’ve made a nice further improvement.
name old time/op new time/op delta
ParseRFC3339-16 44.9ns ± 4% 39.7ns ± 3% -11.51% (p=0.000 n=8+8)
OK, we’ve now not only written a custom time parser, but we’ve also written custom number parsers. That’s surely enough. Definitely done now.
Of course we’re not done.
Ah, but let’s just have another look at the CPU profile.
And let’s take a look at the disassembly.
There are two slice length checks in atoi2 (they’re the calls to panicIndex seen in the green disassembly below).
Isn’t there a trick about that?
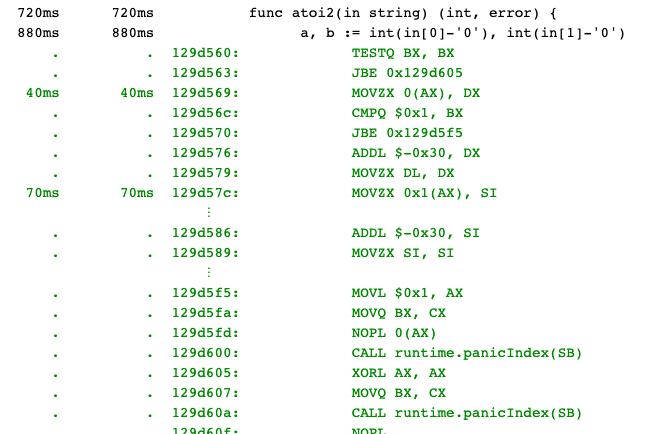
Here’s the code updated with the trick.
_ = in[1] at the start of the function gives the compiler enough of a hint that it doesn’t check the string is long enough each time we reference it later on.
func atoi2(in string) (int, error) {
_ = in[1] // This helps the compiler reduce the number of times it checks `in` is long enough
a, b := int(in[0]-'0'), int(in[1]-'0')
if a < 0 || a > 9 || b < 0 || b > 9 {
return 0, fmt.Errorf("can't parse number %q", in)
}
return a*10 + b, nil
}
A small change, but enough to give a definite improvement
name old time/op new time/op delta
ParseRFC3339-16 39.7ns ± 3% 38.4ns ± 2% -3.26% (p=0.001 n=8+7)
And atoi2 is very short.
Why isn’t it inlined?
Perhaps if we simplify the error it will be?
If we remove the call to fmt.Errorf and replace it with a simple error that
reduces the complexity of our atoi functions.
This might be enough to allow the Go compiler to decide to implement these functions not as separate code blocks but directly within the calling function.
var errNotNumber = errors.New("not a valid number")
func atoi2(in string) (int, error) {
_ = in[1]
a, b := int(in[0]-'0'), int(in[1]-'0')
if a < 0 || a > 9 || b < 0 || b > 9 {
return 0, errNotNumber
}
return a*10 + b, nil
}
This is indeed the case and yields a signficant improvement.
name old time/op new time/op delta
ParseRFC3339-16 38.4ns ± 2% 32.9ns ± 5% -14.39% (p=0.000 n=7+8)
That’s the end of our story. Quite a lot of work for around ~120ns. But nanoseconds add up, and these improvements reduce the running time of some of Ravelin’s machine learning feature extraction pipelines by an hour or more. As I said, we do have a lot of data and a lot of timestamps!