
[]byte versus io.Reader
I'm rooting for the underdog
Everyone loves io.Reader. It’s often touted as people’s favourite thing in Go. But it’s not the best abstraction when you get down to the small. When you’re doing lots of small reads to parse a protocol the overheads are too high, even if you’re using a buffered reader. I think the best abstraction at this point may be []byte, which is essentially no abstraction at all. But lets try using io.Reader and see where that leads us.
Let’s set ourselves a task.
Suppose we want to read a bunch of strings. The strings are encoded as a Varint length followed by that number of bytes. (Varint is an efficient encoding of integers where smaller numbers take up less space). We’ll start by using an io.Reader to access our encoded strings. We’ll define our function as func readString(r io.Reader) (string, error). It turns out there’s a ReadVarint function in encoding/binary. Fabulous, we can use that to read our Varint. Except it takes an io.ByteReader, not an io.Reader.
No matter. We can use interface composition to create an interface that combines io.ByteReader and io.Reader. We can then write our readString function. Here’s our initial readString below. We’ll use a strings.Builder to build the string that we return to our caller.
import (
"encoding/binary"
"io"
"strings"
)
type Reader interface {
io.Reader
io.ByteReader
}
func readString(r Reader) (string, error) {
l, err := binary.ReadVarint(r)
if err != nil {
return "", err
}
var b strings.Builder
b.Grow(int(l))
_, err = io.CopyN(&b, r, l)
return b.String(), err
}
Great, we can read a string! Let’s see how that performs. We’ll write a benchmark that reads a string.
func BenchmarkReadString(b *testing.B) {
data := []byte{16, 'c', 'h', 'e', 'e', 's', 'e', 'i', 't'}
buf := bytes.NewReader(nil)
b.ReportAllocs()
for i := 0; i < b.N; i++ {
buf.Reset(data)
if _, err := readString(buf); err != nil {
b.Fatal(err)
}
}
}
If we run the benchmark (go test -run ^$ -bench BenchamrkReadString) we get the following.
BenchmarkReadString-16 7541395 155 ns/op 80 B/op 4 allocs/op
4 allocations per operation! We really only expect one: we expect to allocate the string. Where are these other allocations? As usual we reach for the profiler.
go test -run ^$ -bench BenchmarkReadString -memprofile mem.prof
go tool pprof -http :6060 blog.test mem.prof
We spin the profiler up and set the samples to show allocated objects.
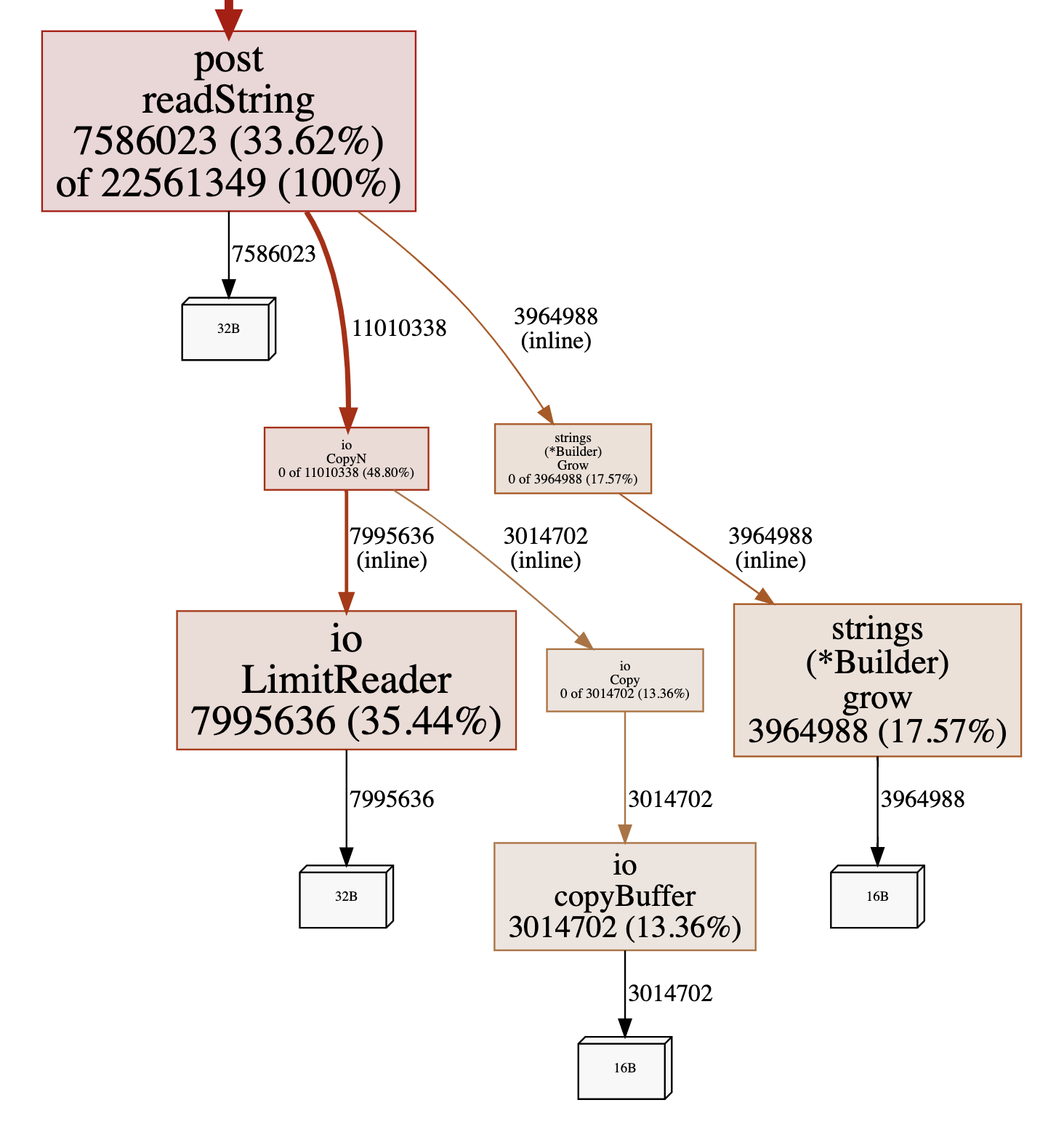
We can see that io.CopyN causes two heap allocations.
- It creates an
io.LimitReader. This is used to wrap the sourceio.Reader. It passes this as anio.Readertoio.Copy. - It calls
io.Copy.io.Copyhas shortcuts that don’t allocate if the source reader implementsWriterTo(which it doesn’t because it’s wrapped in aLimitReader), or if the destination buffer implementsReaderFrom(which it doesn’t because, …, it doesn’t). So it creates a buffer to tranfer data.
readString itself causes a heap allocation because it creates a strings.Builder, which it then passes as an interface to io.CopyN. Both the strings.Builder and io.LimitReader are placed into interface variables, then methods are called on them. This defeats Go’s escape analysis, so both of these are allocated on the heap. The buffer is passed as a parameter on an interface, so again this defeats escape analysis and it is allocated on the heap.
The 4th allocation is the one we expect. We need an allocation for the string itself. This is the call to Grow on the StringBuilder. This is a necessary as we’re returning the string to our caller. We’re not aiming to get rid of this.
Second attempt
Our first attempt was not so great. I picked strings.Builder as it’s intended as a way to build a string without causing an additional allocation converting the []byte you build it in to a string. Before it existed I’d nearly always do a trick with unsafe to avoid that allocation. What if we go back to that older way of operating? Then we can build our string directly in a []byte.
func readString(r Reader) (string, error) {
l, err := binary.ReadVarint(r)
if err != nil {
return "", err
}
b := make([]byte, l)
_, err = io.ReadFull(r, b)
return *(*string)(unsafe.Pointer(&b)), err
}
With this version we avoid using io.CopyN, so hopefully we avoid some allocations. Here’s the new result from the benchmark.
BenchmarkReadString-16 24335883 44.3 ns/op 8 B/op 1 allocs/op
OK, that’s much better. But it still seems quite slow considering what it is doing. Let’s get a CPU benchmark and see what’s going on.
go test -run ^$ -bench BenchmarkReadString -cpuprofile cpi.prof
go tool pprof -http :6060 blah.test cpu.prof
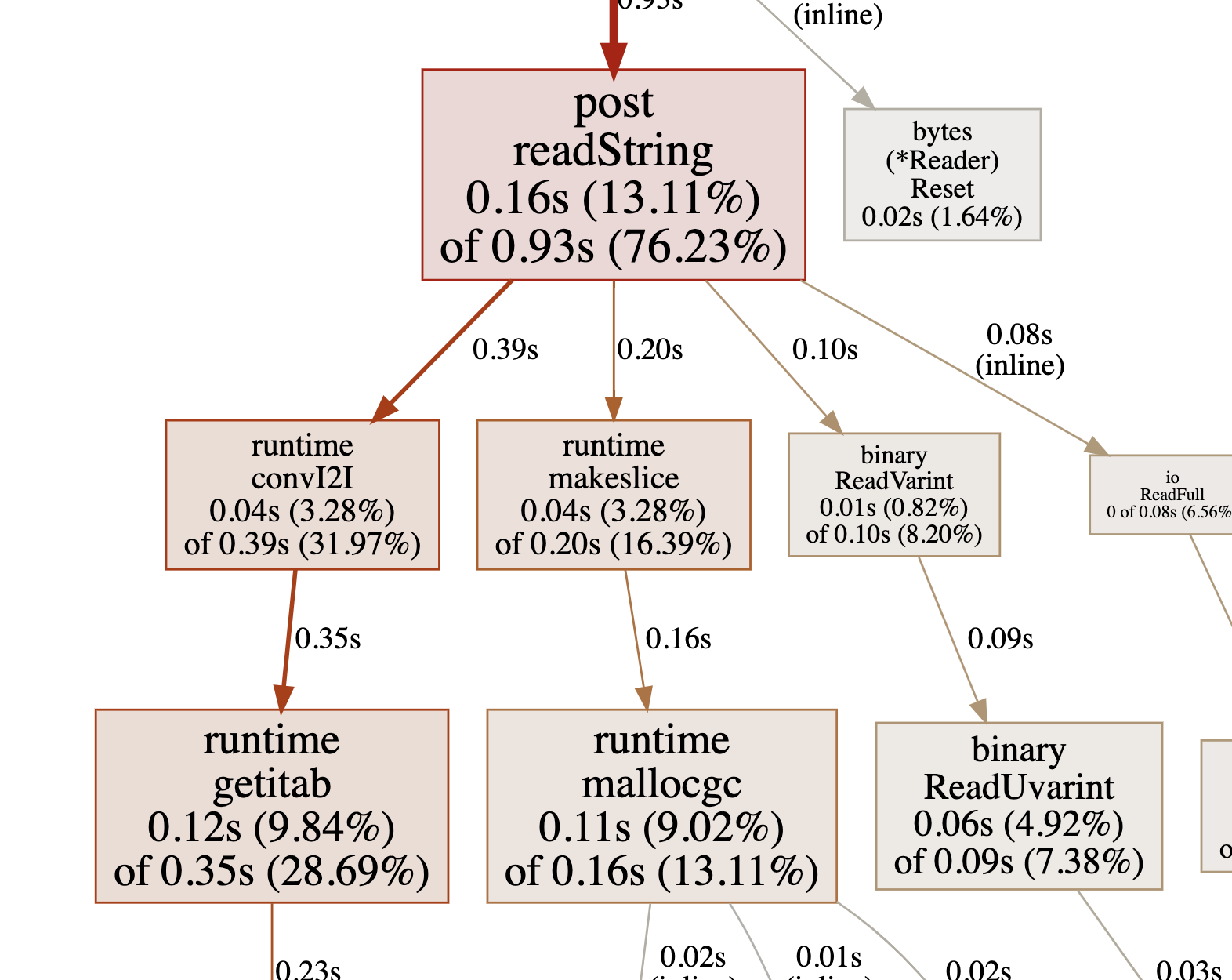
What’s this runtime.convI2I thing? There’s a wonderful blog post here that explains it. It converts one interface to another. I’ve defined my own Reader interface, and I need to convert that to an io.ByteReader to call binary.ReadVarint and to an io.Reader to call io.ReadFull and both of those operations take time.
Third attempt
Say I think I’m always going to be reading these strings from a file. Practically I’d always wrap the file in a bufio.Reader. What happens if I change my function to take this concrete type instead?
func readString(r *bufio.Reader) (string, error) {
l, err := binary.ReadVarint(r)
if err != nil {
return "", err
}
b := make([]byte, l)
_, err = io.ReadFull(r, b)
return *(*string)(unsafe.Pointer(&b)), err
}
Well, the call to runtime.convI2I goes away, but overall it is no faster, probably because I’ve added quite a bit of complexity with layers of readers. If I change the benchmark around a bit to reduce the overhead of resetting the readers things improve.
func BenchmarkReadString(b *testing.B) {
data := bytes.Repeat([]byte{16, 'c', 'h', 'e', 'e', 's', 'e', 'i', 't'}, 1000)
b.ReportAllocs()
r := bytes.NewReader(nil)
buf := bufio.NewReader(nil)
for i := 0; i < b.N; i += 1000 {
r.Reset(data)
buf.Reset(r)
for j := 0; j < 1000; j++ {
if _, err := readString(buf); err != nil {
b.Fatal(err)
}
}
}
}
BenchmarkReadString-16 31674597 33.9 ns/op 8 B/op 1 allocs/op
4th attempt
So what if we go back to basics and accept our data just as a []byte? We don’t need to make any function calls to access the data. But we do need to change our function signature to let the caller know how much data we’ve used. And we need to check there’s enough data to read.
func readString(data []byte) (string, int, error) {
l, n := binary.Varint(data)
if n == 0 {
return "", 0, io.ErrUnexpectedEOF
}
if n < 0 {
return "", 0, fmt.Errorf("invalid length")
}
if n+int(l) > len(data) {
return "", 0, io.ErrUnexpectedEOF
}
// Casting []byte to string causes an allocation, but we want that here as
// we don't want to hold onto the data []byte
return string(data[n : n+int(l)]), n + int(l), nil
}
Here’s the benchmark result.
BenchmarkReadStringC-16 41971776 24.2 ns/op 8 B/op 1 allocs/op
We’re down to about the time it takes for the allocation for the string. The time taken parsing the string is now negligable. And it now takes 1/7th of the time it took when we used interfaces and all the shiny toys from the Go standard libraries.
Don’t get me wrong. io.Reader & io.Writer are both fabulous, and the plug-and-play nature of them can be very convenient. And when moving large chunks of data the overheads are minor. But parsers and marshalers and other low-level things should probably avoid them, or at least provide options to work directly with byte slices.
Bonus content
OK, OK, this post is really over already, but we kind of cheated above. If our data is very large and isn’t framed in some way then perhaps we can’t load complete records into a []byte to process. In those cases we’d need to implement some kind of buffering. But from the lessons above we would want to implement our buffer as a concrete type and have it provide direct access to it’s internal []byte.
The Next() method on bytes.Buffer is a great model here. It lets you see the next n bytes from the buffer directly with no copying, but also allows you to advance the read point. bufio.Reader has Peek() and Discard(), which allows almost the same access but is quite awkward.
I’ve knocked together the following implementation to prove the point. The primary interface to this is Next() which just returns the next l bytes of the internal buffer. It attempts to refill from the underlying reader if not enough bytes are available. Despite dissing on Peek ad Discard I’ve also implemented similar functions here too, as well as a Refill to manually trigger a refill of the buffer from the reader.
func NewBuffer() *Buffer {
return &Buffer{
data: make([]byte, 1000),
}
}
type Buffer struct {
data []byte
i int
r io.Reader
err error
}
func (b *Buffer) Reset(r io.Reader) {
b.data = b.data[:0]
b.i = 0
b.err = nil
b.r = r
}
func (b *Buffer) Next(l int) ([]byte, error) {
if b.i+l > len(b.data) {
// Asking for more data than we have. refill
if err := b.refill(l); err != nil {
return nil, err
}
}
b.i += l
return b.data[b.i-l : b.i], nil
}
// Peek allows direct access to the current remaining buffer
func (b *Buffer) Peek() []byte {
return b.data[b.i:]
}
// Dicard consumes data in the current buffer
func (b *Buffer) Discard(n int) {
b.i += n
}
// Refill forces the buffer to try to put at least one more byte into its buffer
func (b *Buffer) Refill() error {
return b.refill(1)
}
func (b *Buffer) refill(l int) error {
if b.err != nil {
// We already know we can't get more data
return b.err
}
// fill the rest of the buffer from the reader
if b.r != nil {
// shift existing data down over the read portion of the buffer
n := copy(b.data[:cap(b.data)], b.data[b.i:])
b.i = 0
read, err := io.ReadFull(b.r, b.data[n:cap(b.data)])
b.data = b.data[:n+read]
if err == io.ErrUnexpectedEOF {
err = io.EOF
}
b.err = err
}
if b.i+l > len(b.data) {
// Still not enough data
return io.ErrUnexpectedEOF
}
return nil
}
The readString function now looks like the following
func readString(b *Buffer) (string, error) {
l, n := binary.Varint(b.Peek())
for n == 0 {
// Not enough data to read the varint. Can we get more?
if err := b.Refill(); err != nil {
return "", err
}
l, n = binary.Varint(b.Peek())
}
if n < 0 {
return "", fmt.Errorf("blah")
}
b.Discard(n)
if l < 0 {
return "", fmt.Errorf("negative length")
}
s, err := b.Next(int(l))
return string(s), err
}
I’ve also altered the benchmark so the cost of periodically resetting the buffer is spread out, and to force the buffer to read from the reader.
func BenchmarkReadString(b *testing.B) {
data := bytes.Repeat([]byte{16, 'c', 'h', 'e', 'e', 's', 'e', 'i', 't'}, 1000)
b.ReportAllocs()
r := bytes.NewReader(nil)
buf := NewBuffer()
for i := 0; i < b.N; i += 1000 {
r.Reset(data)
buf.Reset(r)
for j := 0; j < 1000; j++ {
if _, err := readString(buf); err != nil {
b.Fatal(err)
}
}
}
}
The benchmark results for this are pretty handy. It’s perhaps slightly slower than using a byte slice directly, but now our parser can work with streaming data.
BenchmarkReadString-16 44789697 27.2 ns/op 8 B/op 1 allocs/op